

Ok, pay attention here as machine learning and analytics continues to grow as the main clients here thus far are healthcare, financial service, and insurance providers. This should come as no surprise as we all know insurers use analytics all the time and have a long extensive history of doing so, in as much as news in the past has denied consumers services based on some of their algorithms and created numerous law suits. Models are not bad if they are accurate and paint a good picture than being used to make money only with little or no regard for the ultimate end consumer who is subject to the criteria entered. When this occurs we end up with the Attack of the Killer Algorithms and a lot of Algo Duping going on with steroid marketing that appears in the news to “sell” said analytics.
financial service, and insurance providers. This should come as no surprise as we all know insurers use analytics all the time and have a long extensive history of doing so, in as much as news in the past has denied consumers services based on some of their algorithms and created numerous law suits. Models are not bad if they are accurate and paint a good picture than being used to make money only with little or no regard for the ultimate end consumer who is subject to the criteria entered. When this occurs we end up with the Attack of the Killer Algorithms and a lot of Algo Duping going on with steroid marketing that appears in the news to “sell” said analytics.
What makes this platform even more interesting is the ability to “sell” your SaaS model creation as well. Ok, so are we going to sell something that makes money or solves problems? It’s the same old issue that we are facing everywhere with models, created by humans or machines. One thing we all have to remember is that things don’t always play out in the real world as they do in formulas as we are humans and there’s a line of “fantasy” at times when reports are created to substantiate the numbers and the math used. It’s all about “context” and if you have not seen the video from NYU professor Siefe, give it a view as it does a good job explaining a lot of this. Here’s the link and it is also permanently embedded in the footer of this blog if you scroll down. We do have to be aware of the “Dark Arts of Mathematical Deception” out there and he was really ahead of his time with the book. Mathematicians and programmers see a lot of things before they get into the news feeds we see for sure. I covered some of this last year too with context being everything.

Here’s yet another informative link about model perceptions and how it interacts with data, well worth reading as this is where the future lies with insisting on accountability with models. I think comments from those (i.e. Quants) who build models for a living will be interesting to hear what they have to say as well. If anyone can get in and give some accurate opinions, they are the ones to do so as they will also know the model that was used t build this model for creating “models” via SaaS.
“It’s Not the Data, It’s the Models Stupid”-Big Data Helps But It Is Not the Answer
We see the over dependence or duping all the time with consumers and the government to where those who are not in the tech field assume that models and algorithms will solve all…good example at the link below and why we really need to start thinking about having executive heads in place with some technology in their backgrounds rather than more attorneys and just flat out figureheads that have to guess and rely on staff for everything. Here’s another yet value question on the Facebook focus here.
HHS Secretary Sebelius Still Looking for Tech Breakthroughs To Save the Day
Here’s another back link below discussing finding “value” in big data as anyone can create a model, but is the value and accuracy present? No blog post should be posted about modeling without including a link to former Wall Street Quant Cathy O’Neill who is helping educate all (me too) on how models can lie and how accountability should be required. You can watch one of her videos here and see what I mean.
Big Data/Analytics If Used Out of Context and Without True Values Stand To Be A Huge Discriminatory Practice Against Consumers–More Honest Data Scientists Needed to Formulate Accuracy/Value To Keep Algo Duping For Profit Out of the Game
Now that we are or will be mass producing “models without borders” I’m going out on a limb a bit here to pretty much predict that the results may end up in the same odds boat that start ups have, in other words sure with some very simplistic models there will be some use but when it comes to models with substantial use with big data, the value found will be far and few between, in other words sure there will be some created with value but there will be a lot more (again I’m focusing on a large data focus here like a successful start up) that will not have any at all other than to reduce risk and make money. In essence we just have another set of tools and how they are used, verified, and the accuracy levels will play out when the verification process really gets going.
Thus, the Australian bankers I think were right when they said that half of all analytics expenditures will be a waste of money. No matter what you come up with, it still has to play out in the “human” world. You can do anything with software said Mike Orsinski who wrote the sub prime model and software that all the banks used…keep that thought and scroll down to the footer and watch the Alchemists of Wall Street Documentary below and it will make more sense as this is the only video I have found that really nails it simply for the layman to get an idea of what goes on behind “closed server doors” if you will. As the full article mentions, this is only one site and there are other companies doing the same thing so it appears we are entering the world of “mass model production” or as Cathy O’Neill has coined, “Methods of Math Destruction” in her lectures. You can also catch her PBS interview in the footer here as well. Machine learning does make mistakes too, read about my own encounter with Google and how their machine learning thought I was a fowl, and this post has had many a tech person chuckling by all means, as it does happen. Now the Google learning algorithm knows that duck can also be a human and I guess I need to conform to a machine compatible name? (grin) BD
they said that half of all analytics expenditures will be a waste of money. No matter what you come up with, it still has to play out in the “human” world. You can do anything with software said Mike Orsinski who wrote the sub prime model and software that all the banks used…keep that thought and scroll down to the footer and watch the Alchemists of Wall Street Documentary below and it will make more sense as this is the only video I have found that really nails it simply for the layman to get an idea of what goes on behind “closed server doors” if you will. As the full article mentions, this is only one site and there are other companies doing the same thing so it appears we are entering the world of “mass model production” or as Cathy O’Neill has coined, “Methods of Math Destruction” in her lectures. You can also catch her PBS interview in the footer here as well. Machine learning does make mistakes too, read about my own encounter with Google and how their machine learning thought I was a fowl, and this post has had many a tech person chuckling by all means, as it does happen. Now the Google learning algorithm knows that duck can also be a human and I guess I need to conform to a machine compatible name? (grin) BD
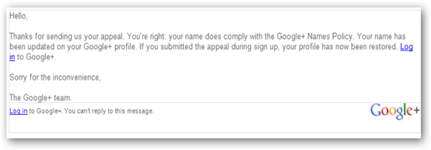
“I’m Sorry Your Google Plus Name Does Not Comply With Google “Names Policies”…Barbara “Duck Algorithm” & Was Using My Real Name All Along…Killer Algorithms Chapter 52
Machine learning has historically resided within the realm of the data scientist, a Ph.D.-wielding expert trained to glean insights from big data. But with the rapid expansion of digital information, a move is on to democratize data science tools and put the average business analyst on par (almost) with the data expert.
That's the mission of BigML, a Corvallis, Ore.-based startup with a SaaS-based machine learning platform that allows everyday business users to create actionable predictive models within minutes.
BigML opened for business in October 2012 and currently has 3,500 registered users, approximately half of whom have created models. More than 20% of those users have uploaded their own data sources, the company says.
The service is free to try. To get started, you upload data (e.g., an Excel spreadsheet) to BigML's website and create a data set. (Setup can get tricky for novices, and video tutorials are provided.) BigML's interface has several easy-to-use tools such as "one-click" buttons for creating data sets and predictive models. You can change things about your data as well, such as the data set's descriptive name and parsing options.
After creating a model, you can download it for local usage, or share and/or sell it in BigML's public gallery. "There's a big social component to what we're doing, which is the ability to share your model. I can make [a model] available to anybody to use or buy through the gallery on our website," said Shikiar.
BigML's fees are based on the number of "credits" that a customer uses. For instance, 1 TB of space to create datasets equals 1,048,576 credits; 1 TB of data to create new models is 4,194,304 credits; and you'll need 10,000 credits to generate 1 million predictions. The credit total: 5,252,880. Multiple that number by 0.1 cents, and your bill comes to $5,252.88.

0 comments :
Post a Comment